

利用高光谱数据增强目标检测并提升机器视觉训练效率
在机器视觉领域,模型能力的提升往往需要更多的数据、更高的成本、更长的训练周期。但如果数据本身的信息密度就不够,再多的样本真的能够解决问题吗?这正是当前以RGB为核心的计算机视觉体系所面临的结构性瓶颈。而高光谱成像正是从“数据源头”改变机器视觉的训练逻辑。

计算机视觉开发人员面临的挑战
· 对大型数据集的依赖推动了训练成本高昂的算法的发展,限制了通用检测模型的可用性,使其仅适用于标记广泛、范围广的对象类别。
· 对于普通的计算机视觉 (CV) 开发人员来说,这带来了巨大的挑战。大多数开发人员只能访问数量有限的带标签图像——通常只有几十张、几百张,或者运气好的话几千张。这远少于用于训练 Segment Anything (SAM) 的十亿张图像,甚至少于 2012 年 AlexNet 使用的 120 万张图像。Ultralytics 公司的 YOLO 至少使用了 MSCOCO 数据集的 32.8 万张图像进行训练(而且可能更多)。如果从头开始标注这些数据,按每张图像 1.33 美元的合理价格计算,总成本将达到 43.6 万美元。
· 训练这些模型所需的庞大计算资源和数据量往往超出开发者的承受范围。在农业科技、医疗和安全等专业领域,这种情况更为严峻。在这些领域,数据需要专家标注,可能需要严格的保密控制,而且准确检测罕见类别至关重要,这进一步推高了标注成本和达到所需准确率所需的数据量。
· 对比 AlexNet 和 SAM 的数据需求,我们发现,训练深度学习系统需要的数据量越来越大,这是一个趋势。
· 从根本上讲,任何仅基于RGB数据的计算机视觉算法都会面临这些问题,因为无论使用多少图像或计算资源,都无法弥补RGB图像本身缺失的信息。高光谱信息则能有效解决这个问题,因为每个光谱都包含额外的信息。
高光谱数据如何解决这些问题?
高光谱成像(HSI)提供了一个额外的维度,可用于光谱的分割和分类。物体的反射光谱包含其化学成分信息,显示哪些频率的光被吸收,哪些频率的光被反射。这种丰富的颜色信息使得区分 RGB 中不可见的对象子类变得容易,并且消除了对形状信息的依赖,这意味着遮挡不再是一个问题。
高光谱成像的特性决定了可以通过反射率转换来降低光照变化的影响。因此,不再需要大量的训练数据来实现高精度成像。此外,光谱中包含的色彩信息量更大,这使得机器学习算法的工作更加轻松。这类似于区分彩色图像中的红色铅笔和绿色铅笔,而不是区分黑白图像中的红色铅笔和绿色铅笔。
区分苹果品种:HSI 与 RGB 色彩空间

我们以区分不同品种的苹果为例,虽然在RGB 中区分 Granny Smith 和 Pink Lady 可能很简单,但区分 Royal Gala、Jazz 和 Pink Lady 就比较困难了。 使用RGB识别苹果相对容易,“苹果”是YOLO软件预置的1000个类别之一。但是,如果你想区分不同类型的苹果,例如,防止人们在自助结账时购买廉价苹果而拿走昂贵的苹果,那么RGB识别就无法满足需求了。
据估计,自助结账盗窃每年给零售商造成19.7亿美元的损失。虽然计算机视觉可以用于解决这个问题,但仅使用RGB技术可能无法提供所需的精度。这会导致顾客不满,因为自助结账机不断提示“装袋区发现意外物品”。 幸运的是,高光谱数据使得区分不同品种的苹果(以及其他农产品)变得轻而易举。这使得基于高光谱成像技术的计算机视觉技术成为零售业的变革性技术。
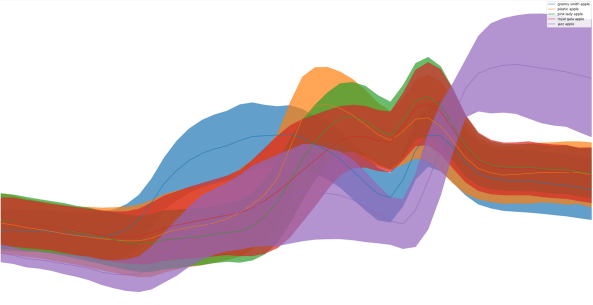
不同品种苹果的光谱曲线
光谱的可分离性使我们能够利用简单的随机森林分类器来区分苹果品种。将光谱检测与现成的RGB分割方法相结合,仅使用100张训练图像从头开始训练,即可得到如下所示的结果。
该案例验证了 Living Optics 高光谱相机在标准计算机视觉流程中的可集成性,以及高光谱数据对模型训练效率提升的实际价值。无需大规模数据扩充或复杂网络结构调整,即可获得更高的信息利用率与更优的分类表现。
如果您希望进一步了解高光谱成像技术在目标检测、分类识别或行业应用中的具体实践路径,欢迎与我们交流,共同探讨其在实际业务场景中的落地方案。
-

快照式视频高光谱相机对各行业的影响及其颠覆性应用
Living Optics——更快、更便携、更易用的快照式视频高光谱相机 。虽然高光谱成像技术已经存在很长时间了,但传统方法限制了其应用。值得庆幸的是,随着新型快照成像技术的出现,高光谱成像技术已准备好发展成为一项在众多行业中都不可或缺的宝贵技术。
넶52 2026-06-30 -

TELOPS 红外热像仪
TELOPS(泰洛普斯)2000 年创立于加拿大魁北克市,现隶属于 Exosens 集团,是全球顶尖科研级制冷型红外成像设备厂商,专精高速红外、多光谱、高光谱红外探测系统,产品面向高校科研、航空航天、国防、工业精密测试、环境监测领域,中国区官方总代理为北京锐盛光电科技有限公司。
넶66 2026-06-23 -

视频高光谱 AI边缘计算在农业科研中的三大优势
从提前预警作物风险、田间便捷检测,到联动智能技术搭建农业数据体系,高光谱成像以三大核心优势,彻底革新传统农业科研模式。在全球粮食紧缺的大环境下,这项技术将持续赋能智慧农业,实现增产、降耗、提质,为粮食安全筑牢技术防线。
넶26 2026-06-17 -

Telops高速红外热像仪全工况制动系统测温方案
Telops高速红外热像仪凭借微秒级成像、超高帧频与宽温域能力,在汽车安全气囊(毫秒级起爆)与刹车系统(高频摩擦热)测试中,实现瞬态热过程捕捉、温度场量化与失效溯源,是研发与认证的核心设备。
넶16 2026-06-17 -

如何借助Chronos 2.1-HD高速相机实现火箭自主着陆?
随着航空航天、先进制造、流体力学以及燃烧研究的发展,高速成像技术的应用范围也在不断扩大。Chronos 2.1-HD支持1920×1080分辨率下1000fps高速拍摄,同时具备紧凑化设计,可适应实验室与外场测试等多种应用环境。
넶20 2026-06-03 -

「光谱之眼,空中洞察」Living Optics 让无人机拥有“光谱视觉“
本次无人机\x26amp;Living Optics高光谱集成方案,真正做到: 轻量化、易上手、高稳定、高精度。打破了传统高光谱设备 “笨重、难用、门槛高” 的壁垒,让专业级高光谱遥感真正走进低空作业场景。
넶28 2026-06-03 -

OGI GasCore:TELOPS全新红外气体泄露检测机芯,洞悉无形之气,守护核心安危
在能源转型的关键时期,安全与环保是石油化工企业的生命线。OGI GasCore以其领先的NECL指标、灵活的集成能力和专业的光谱技术,为油气与化工行业建立了更高灵敏度、更高可靠性、更高集成度的遥感检测标准。
넶30 2026-05-22 -

Freefly 已正式加入L-Mount联盟
넶47 2026-05-09 -

全天候大气探测新方案:Telops ASSIST II 可用于外场部署的高光谱探测仪
Telops ASSIST II 作为新一代可用于外场部署的大气探测光谱仪,凭借先进的傅里叶变换红外(FTIR)技术,为大气观测提供了更加精准、高效的解决方案。
넶50 2026-05-08 -

从单点测量到全场检测:轮胎热检测技术的全新升级
高速红外热像仪通过非接触、高帧频、全场测温等优势,在轮胎研发、耐久测试、在线安全预警与故障诊断中实现 “热CT” 级检测,可精准捕捉高速旋转胎面的瞬态温场、热点与缺陷,是轮胎性能优化与安全防控的核心。
넶54 2026-05-08













